

image courtesy of itpro.co.uk
Today’s business leaders can be inundated with large data sets presented to them and challenged to determine the best tools to manage and analyze the data. To stay competitive, they need to use historical information to reveal patterns and trends for the future. Understanding and interpreting data have become a vital process for business although some may become intimidated by the amount of data available. Traditionally, data is owned by the IT department of the business. Today, other departments within a business such as human resources (HR), marketing or sales require this information and want it without the delay of IT intervention. This has created the need for non-IT business managers to be acquainted with technical terms and processes previously understood only by the IT department. The vernacular of IT and the speed it changes can be as overwhelming as the data itself. In this brief article, I will introduce three of the most common data terms and define each.
Big Data
Big data is one of several terms in the cloud computing category whose meaning has been diluted with its overuse. I define big data as data sets that are stored by a business for analysis to predict future patterns and trends. I believe the term big data was first introduced as the data businesses needed to manage became too large for its traditional data processing applications. This can be partially ascribed to the fact that in the last two years 90% of the current electronic data has been created. Data capacity and data transmission speed have changed more than any other single technology in IT. For instance, my first computer had a 30 MB hard drive, enough storage for about 20 of the 500 pictures on my smart phone today. It seems like each year we are forced to learn a new term for data capacity. Here are the terms we hear most often today as it relates to the size of data files:
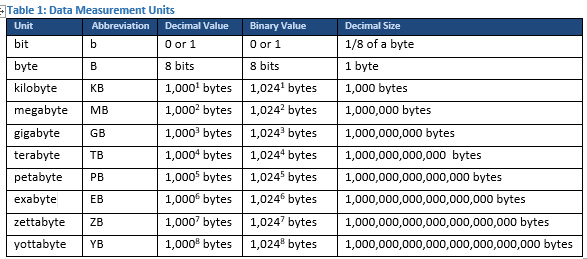
**chart courtesy of techterms.com
In addition to the vast amounts of data businesses need to analyze there are other challenges to big data. First, the variety of forms the data can take such as text, images, and video can test a company’s systems. Additionally, today’s regulatory trends protecting data privacy complicate procedures and policies for the enterprise to store big data. Businesses today storing and analyzing the data must be familiar with the regulations and best practices to protect the identities of all users within the data. Big data has become a tool for creating critical insight for business, but if not managed well it can be more problematic than useful.
Metadata
The simplest definition of metadata is information about the data. Metadata is typically considered to be one of two forms, descriptive or structural. A common example of descriptive metadata is contained in the pictures we take with our smart phones. The picture has additional information attached (metadata) that will describe the time, location and even information about the camera that took the photo. An example more applicable to business users is a column heading of a spreadsheet, this metadata contains vital information needed in understanding the primary data in the spreadsheet. Information stored in a Word document describing who created the document and when it was created is another common example of metadata. These examples provide good insight as to some of the privacy concerns of stored data. It is not uncommon for personal identifiable information (PII) to be hidden in metadata in data files. If not properly secured it will create exposure to breaches and violations of IT regulations.
Structural metadata can be more complicated, it describes data objects or components of the files. Like a book has a table of contents, chapters and pages, structural metadata can guide managers through and help define the components of large data files. Structural metadata is often used in big data applications such as databases which can offer little value without systems to identify components of value to the different business units within an organization. These systems, most times based in a software package, are referred to as data modeling.
Data Modeling
Data modeling is defined as the process of creating a software framework for data information systems by applying formalized techniques. The data modeler will define and analyze the requirement for each unique business unit and initiate processes to allow them to get the most benefit from the data. Data modeling is typically a customized application. There are some off-the-shelf data modeling packages, but they tend to be of little use without customization by an expert.
As data grows so does the insight it offers the business for their future trends. It can also grow out of control if not managed properly, creating substantial risk for the business. As businesses collect and use the data they also need to engage experts to mitigate this risk. A trusted advisor and expert can offer best practices for storing, retrieving and analyzing big data. Two Ears One Mouth IT Consulting will meet with you, discover and understand your data needs and guide you to the right partner and processes to provide these services.
Contact @ Jim Conwell (513) 227-4131 jim.conwell@twoearsonemouth.net
we listen first…

Always helps to have a common understanding of common terms when dealing with clients!
LikeLike